selenium p标签_[Python爬虫] Selenium库也太好用了吧!



这篇文章的分享包含如下几个方面:
1、使用Selenium库进行HTML元素定位
2、使用Selenium库模拟鼠标事件
3、使用Selenium模拟移动端触摸操作
4、使用BeautifulSoup库进行HTML解析
文末开启了赞赏功能,先自己给自己点个赞去,哈哈!
今天更新啦!!!
最近两周都没有时间更新公众号,
都害怕自己给忘记了哈哈。
最近在研究APP中H5页面的数据抓取,当依旧使用之前的思路,用Selenium库进行页面元素的定位和操作时,经常出现“Element is not visible”的错误。移动端的数据很多是动态加载的,有时候需要当页面滑动到一定位置时,有些元素才能可见。所以这个时候,我们就需要模拟移动端触摸操作了。Selenium在模拟鼠标操作和移动端触摸操作时,真的很好用,忍不住赶紧分享一下。
真的不能太友好了,对于不懂抓包、JSON等等专业知识的外行来说,使用Selenium库进行数据抓取,简单实用。只要能用浏览器打开的链接,数据抓取都不是问题呀。对于简单的数据抓取,不管是网页版,还是移动端的H5页面,我感觉Selenium+Beautifulsoup的搭配对于业余爬虫人员是万能的了。
页面元素定位
Selenium库进行页面元素的定位是最常用的。爬虫和自动化测试经常使用到。
以京东品类秒杀页面为例子,如果我需要定位到如图商品位置(图中左侧红框标出),然后点击进去商品页面。F12键打开开发者工具可以看到,它的class属性值为“seckill_recommmend_cover”,可以使用driver.find_element_by_class_name方法定位到标签,然后click操作。在这之前可以将浏览器调整到手机模式。
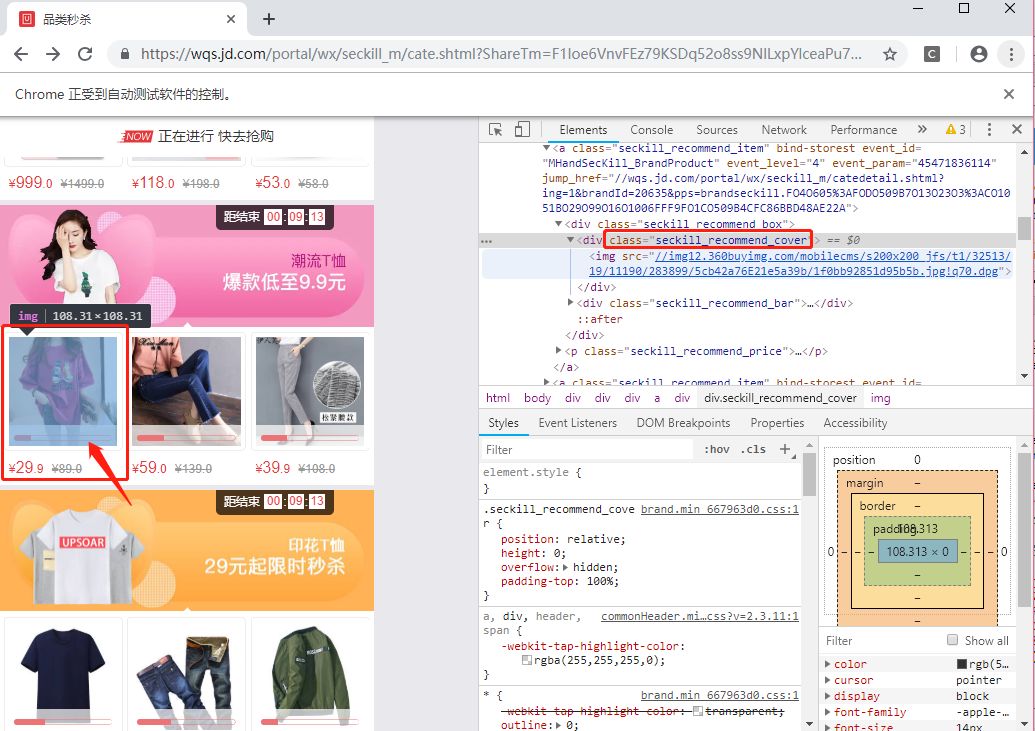
代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.touch_actions import TouchActions
from selenium.webdriver.common.action_chains import ActionChains
from bs4 import BeautifulSoup
##将浏览器切换到手机模式
mobile_emulation = {"deviceName":"iPhone 6"}
options = Options()
options.add_experimental_option("mobileEmulation", mobile_emulation)
driver = webdriver.Chrome(r"C:\\Users\\A\\Downloads\\chromedriver_win32_1\\chromedriver.exe",chrome_options=options)#电脑需要先安装好chromedriver
##以京选品类秒杀页面为例
driver.get("https://wqs.jd.com/portal/wx/seckill_m/cate.shtml?ShareTm=F1Ioe6VnvFEz79KSDq52o8ss9NlLxpYlceaPu74rR85gVStqMYGxlFXPNpNSVWNR7F16bbyJpFbvh8s14GDJRcSw48aksXQcQLcSPa34nkISLzTPcTSKOt5zFaIzkWtqKMnzhULwIs4W13x%2F%2BOmvNQ%2Bv9hgdlYSIR4cbuThBYwo%3D&ad_od=share&utm_source=androidapp&utm_medium=appshare&utm_campaign=t_335139774&utm_term=Wxfriends")
driver.find_element_by_class_name("seckill_recommend_cover").click()
实际效果如下:
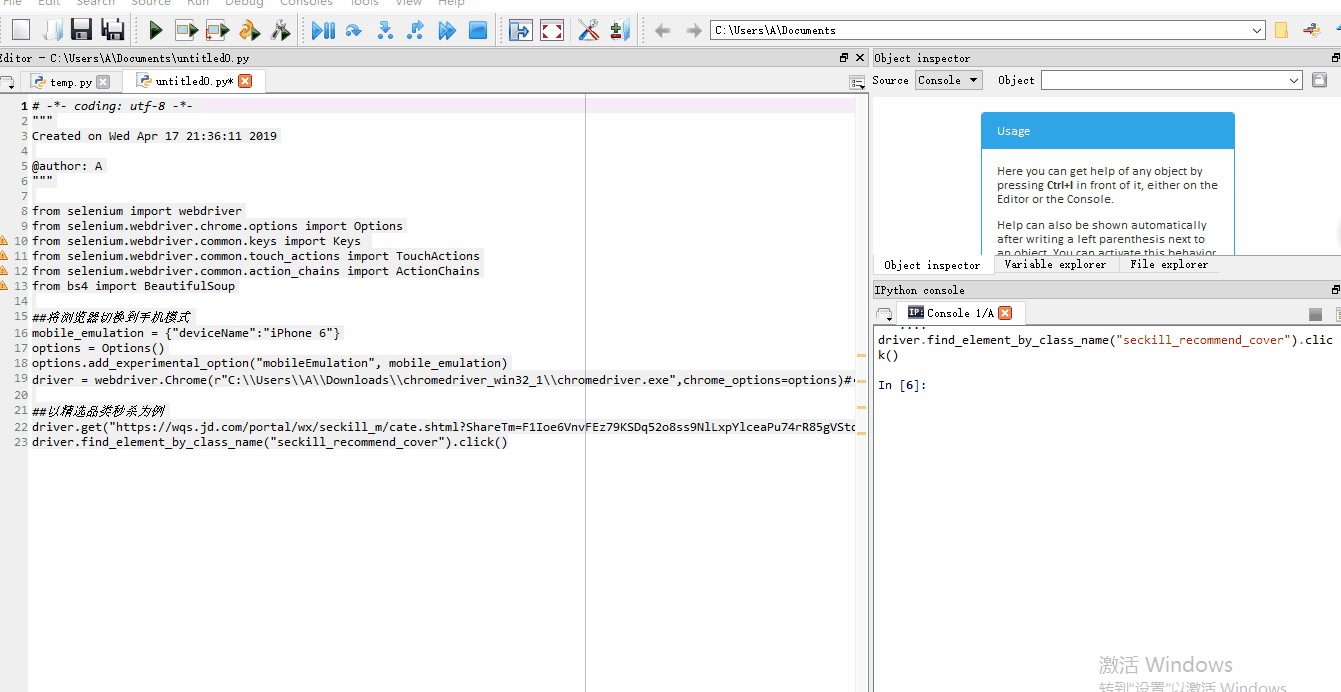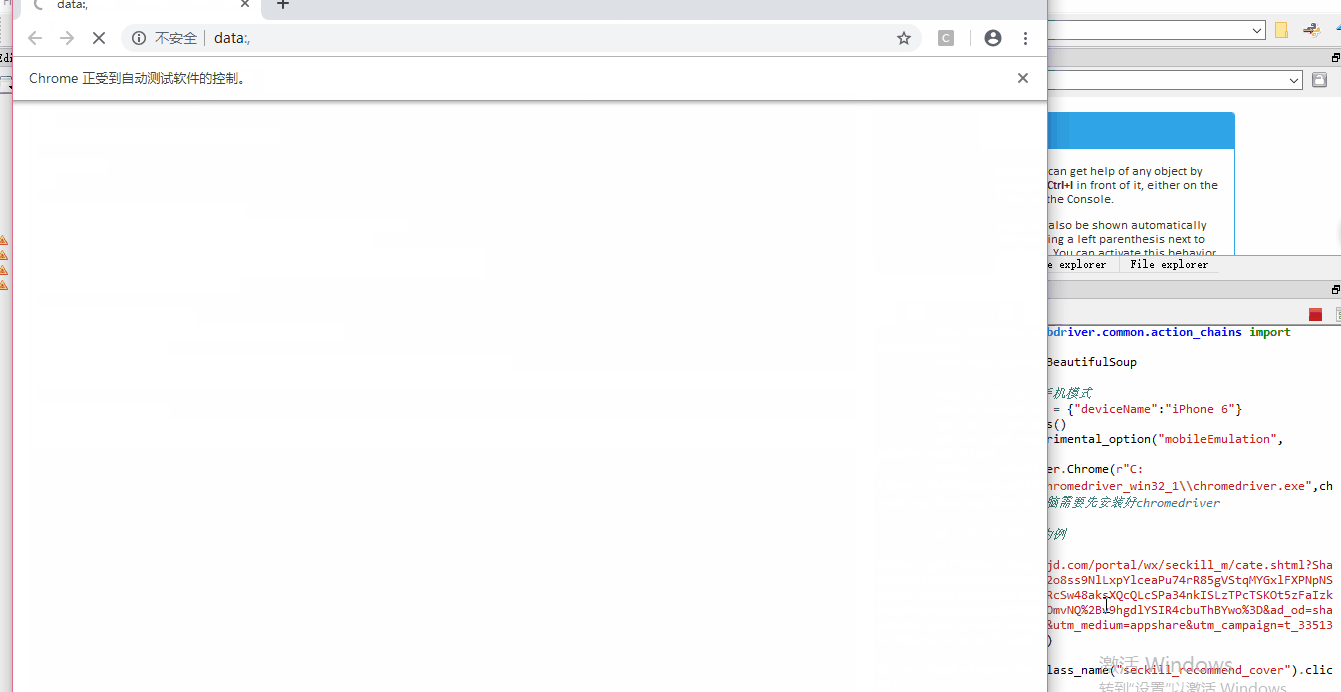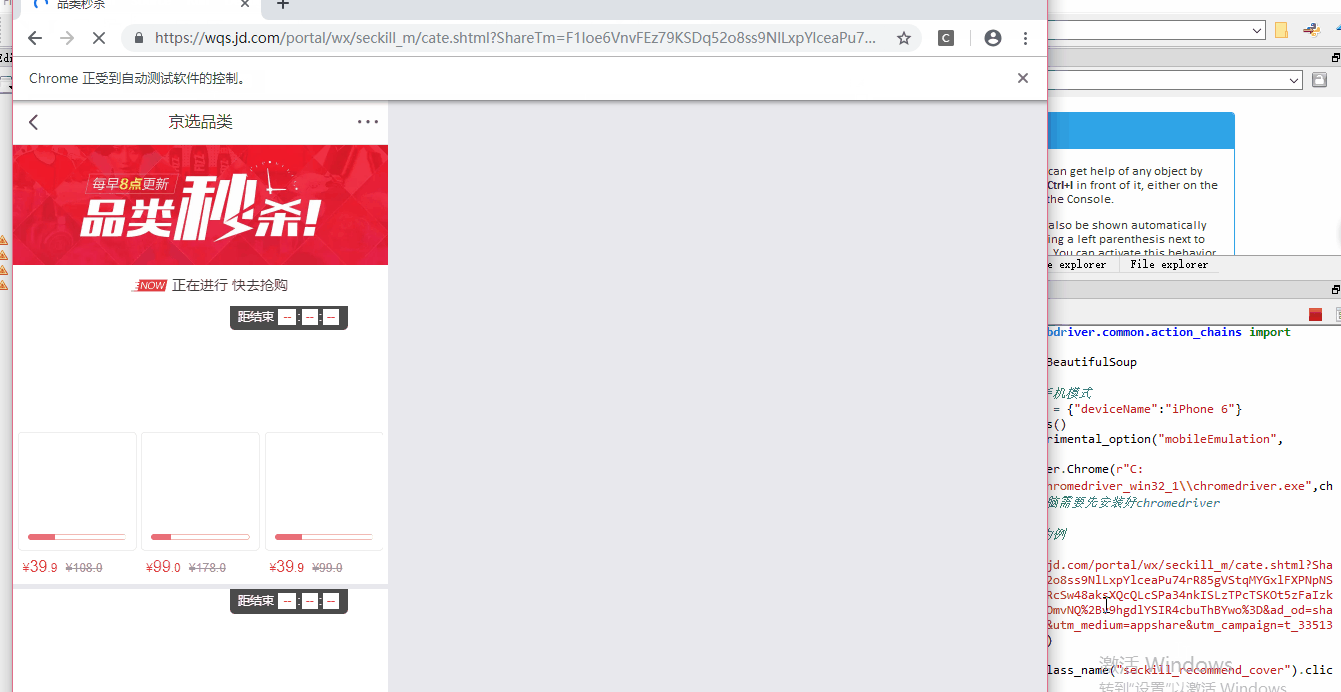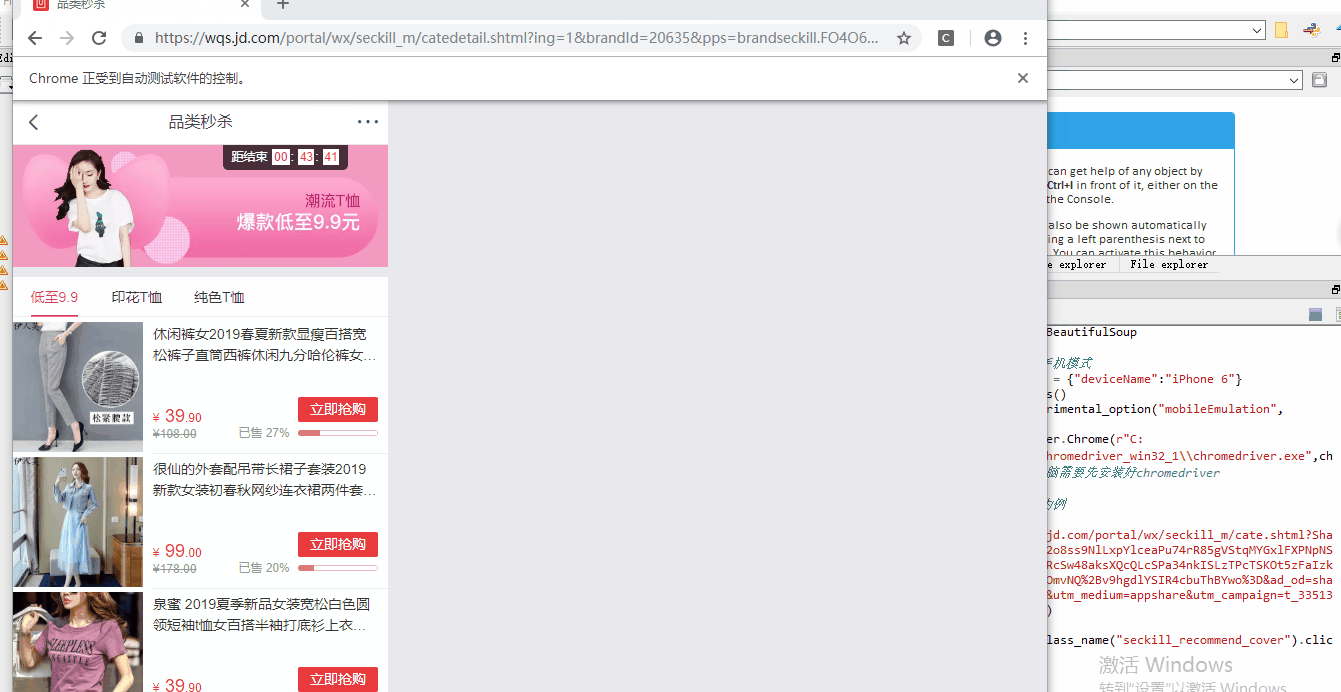
selenium提供了多种元素定位的方式。可以根据属性class的值定位,也可以根据ID定位,或者根据文本定位等。使用这些方法定位元素之后,再使用BeautifulSoup就可以进行页面解析啦。
#基本方法定位
driver.find_element_by_css_selector(driver.find_element_by_css_selector(".某某某")#根据class属性值定位
#xpath定位https://blog.csdn.net/huiseqiutian/article/details/73739707https://www.cnblogs.com/hanmk/p/8997786.htmlfind_element_by_xpath("//标签名[@属性='属性值']")#根据绝对路径定位find_elements_by_xpath(我做的爬虫任务,使用到class_name或者css_selector定位一般就够了,但是有时候针对特定任务,可能需要根据文本值进行匹配或者模糊匹配,这个时候使用xpath定位方法会比较好用。
这里还要注意的是find_element_by和find_elements_by的差别。前者只会定位到第一个满足条件的元素,后者会定位到所有满足条件的元素,返回结果是一个列表。
模拟鼠标事件
有时候在爬取数据的时候,某些属性得鼠标移动到指定位置才会出现。这个时候可以使用selenium ActionChains来模拟操作。
比如我要访问百度页面,然后将鼠标移动到右上角的“”更多产品”位置。这个时候页面会出现更多页面元素。
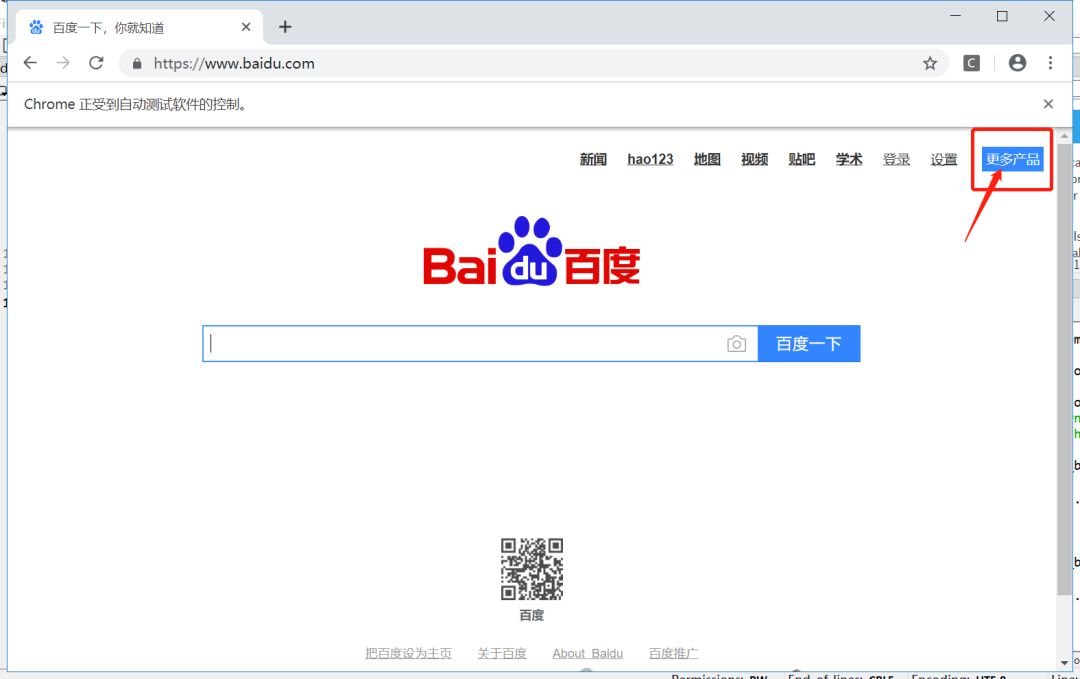
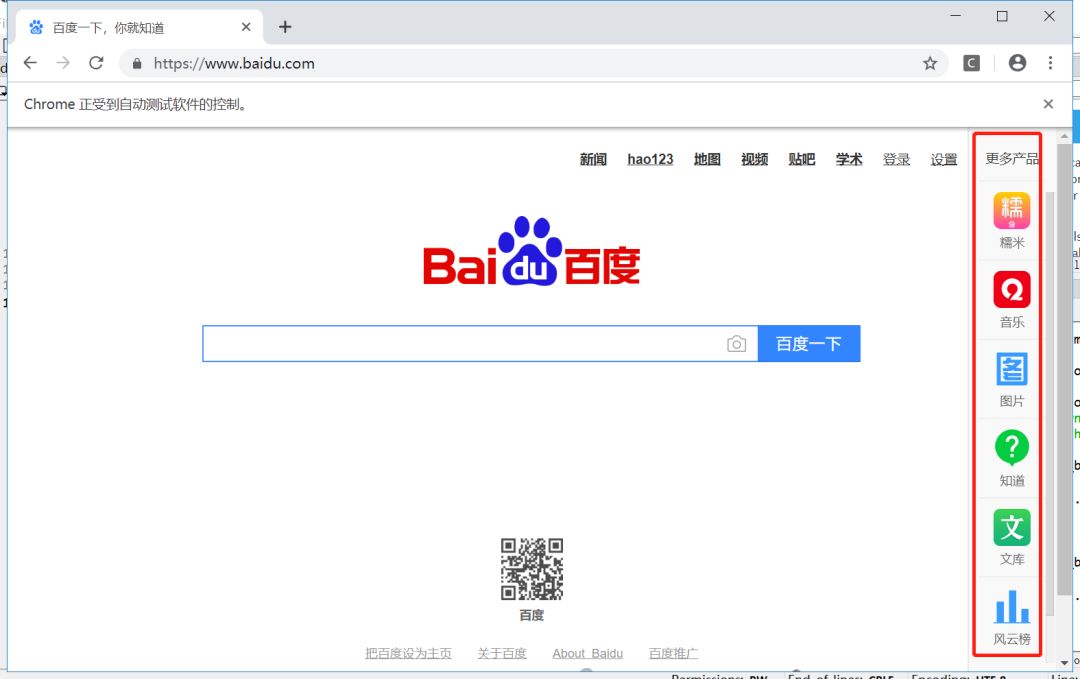
F12打开开发者工具可以看到,“更多产品”在HTML中对应的class属性值是”bri“,我们可以使用class属性值定位。也可以使用链接文本”更多产品“进行定位。
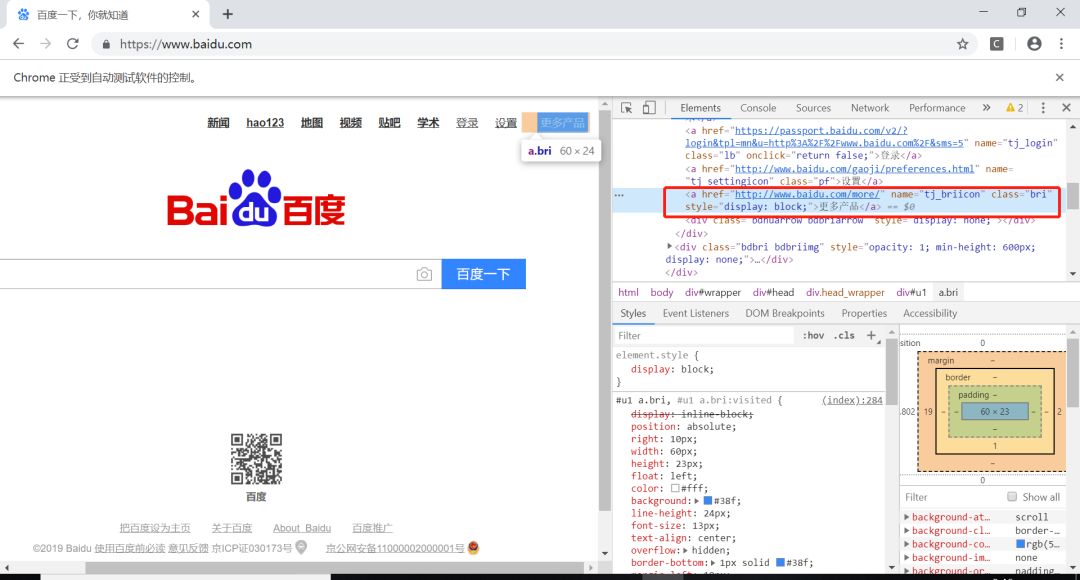
代码如下:
from selenium.webdriver import Chrome
from selenium.webdriver.common.action_chains import ActionChains
driver = Chrome(r"C:\\Users\\A\\Downloads\\chromedriver_win32_1\\chromedriver.exe")
driver.get("https://www.baidu.com/")
element = driver.find_element_by_class_name("bri")
#element = driver.find_element_by_link_text("更多产品")
ActionChains(driver).move_to_element(element).perform()
ActionChains提供的常用操作如下:
可参考:https://www.cnblogs.com/zhongyehai/p/9163740.htmlhtt# perform() 执行所有ActionChains存储的行为。我们可以链式地编写鼠标操作。最后加上perform()。如ActionChains(driver).move_to_element(element).click(element).perform()另一个简单例子,我想从页面顶端的”京选品类“栏移动到第三个秒杀活动Banner处。
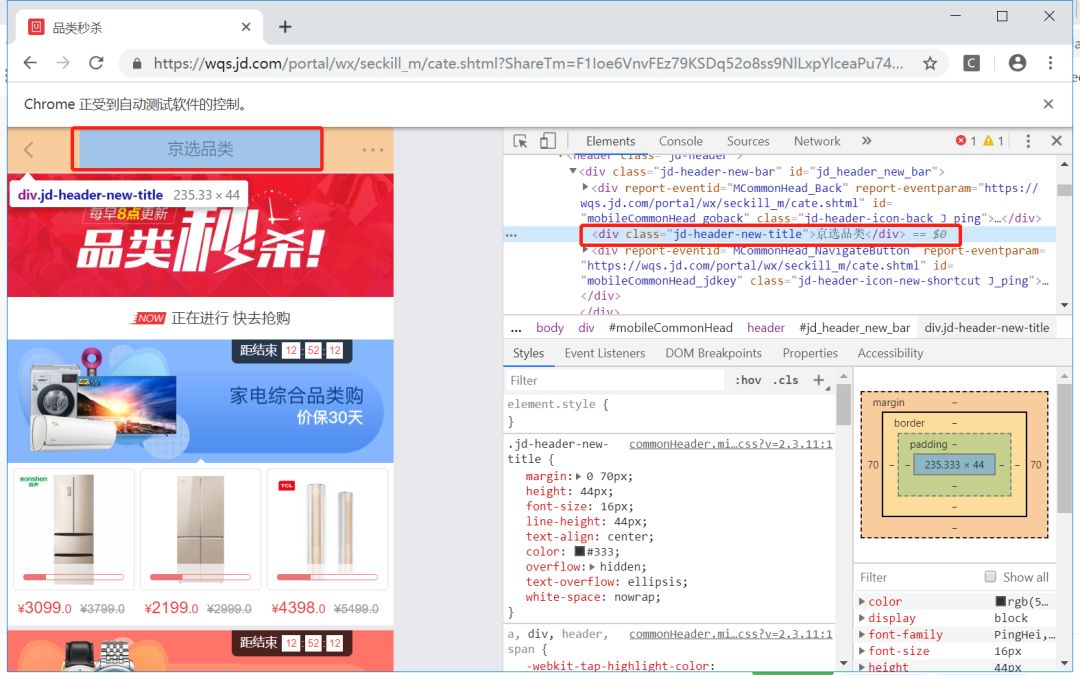
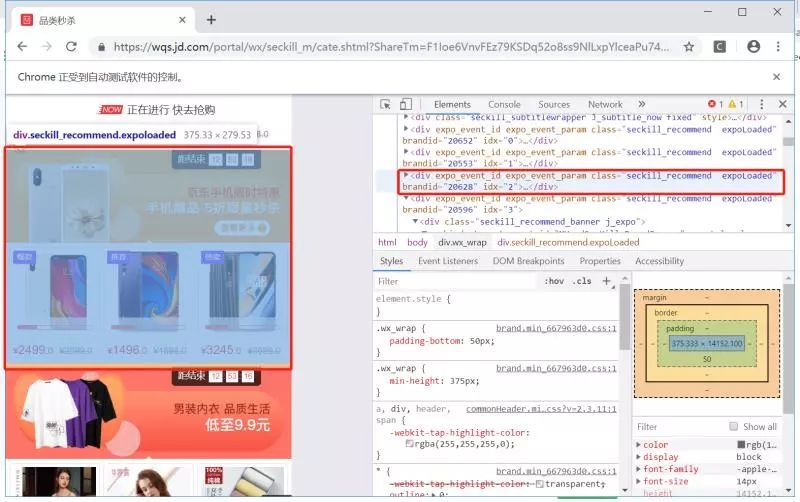
代码如下:
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.touch_actions import TouchActions
##将浏览器切换到手机模式
mobile_emulation = {"deviceName":"iPhone 6"}
options = Options()
options.add_experimental_option("mobileEmulation", mobile_emulation)
driver = Chrome(r"C:\\Users\\A\\Downloads\\chromedriver_win32_1\\chromedriver.exe",chrome_options=options)#电脑需要先安装好chromedriver
##以京选品类秒杀页面为例
driver.get("https://wqs.jd.com/portal/wx/seckill_m/cate.shtml?ShareTm=F1Ioe6VnvFEz79KSDq52o8ss9NlLxpYlceaPu74rR85gVStqMYGxlFXPNpNSVWNR7F16bbyJpFbvh8s14GDJRcSw48aksXQcQLcSPa34nkISLzTPcTSKOt5zFaIzkWtqKMnzhULwIs4W13x%2F%2BOmvNQ%2Bv9hgdlYSIR4cbuThBYwo%3D&ad_od=share&utm_source=androidapp&utm_medium=appshare&utm_campaign=t_335139774&utm_term=Wxfriends")
element1 = driver.find_element_by_xpath("//*[text()='京选品类']")
element2 = driver.find_element_by_xpath("//div[@idx='3']")
ActionChains(driver).drag_and_drop(element1,element2).perform()
模拟移动端触摸操作
在爬取移动端的时候,需要进行一些模拟触摸操作,如将页面下拉、上滑、长按等操作。这个时候可以使用selenium TouchAction来模拟操作。
简单例子:
import time
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.touch_actions import TouchActions
##将浏览器切换到手机模式
mobile_emulation = {"deviceName":"iPhone 6"}
options = Options()
options.add_experimental_option("mobileEmulation", mobile_emulation)
driver = Chrome(r"C:\\Users\\A\\Downloads\\chromedriver_win32_1\\chromedriver.exe",chrome_options=options)#电脑需要先安装好chromedriver
##以京选品类秒杀页面为例
driver.get("https://wqs.jd.com/portal/wx/seckill_m/cate.shtml?ShareTm=F1Ioe6VnvFEz79KSDq52o8ss9NlLxpYlceaPu74rR85gVStqMYGxlFXPNpNSVWNR7F16bbyJpFbvh8s14GDJRcSw48aksXQcQLcSPa34nkISLzTPcTSKOt5zFaIzkWtqKMnzhULwIs4W13x%2F%2BOmvNQ%2Bv9hgdlYSIR4cbuThBYwo%3D&ad_od=share&utm_source=androidapp&utm_medium=appshare&utm_campaign=t_335139774&utm_term=Wxfriends")
element1 = driver.find_element_by_xpath("//*[text()='京选品类']")
TouchActions(driver).scroll_from_element(element1, 0, 200).perform()#向下滑动200个像素,以50的速度向下滑动
time.sleep(5)
driver.close()
TouchAction提供的常用操作如下:
可参考:https://www.cnblogs.com/mengyu/p/8136421.html
# perform() 执行所有ActionChains存储的行为。我们可以链式地编写鼠标操作。最后加上perform()。如ActionChains(driver).move_to_element(element).click(element).perform()
TouchAction的其他移动端操作:
double_tap(on_element) #双击
flick_element(on_element, xoffset, yoffset, speed) #从元素开始以指定的速度移动
long_press(on_element) #长按不释放
move(xcoord, ycoord) #移动到指定的位置
release(xcoord, ycoord) #在某个位置松开操作
scroll(xoffset, yoffset) #滚动到某个位置
scroll_from_element(on_element, xoffset, yoffset) #从某元素开始滚动到某个位置
tap(on_element) #单击
tap_and_hold(xcoord, ycoord) #某点按住
HTML解析
在完成指定的鼠标事件和触摸操作之后,我往往是使用BeautifulSoup库再进一步进行HTML元素的定位和数据抓取。
常用BeautifulSoup库方法就是find和findAll。它们的区别类似find_element_by和find_elements_by。
from selenium.webdriver import Chrome
from bs4 import BeautifulSoup
driver = Chrome(r"C:\\Users\\A\\Downloads\\chromedriver_win32_1\\chromedriver.exe")
driver.get("https://www.baidu.com/")
b = BeautifulSoup(driver.page_source,"html.parser")
b.find('a',class_="bri").get_text()#获取class值为bri的标签的文本内容
b.find('a',class_="bri").get("href")#获取class值为bri的标签的链接
b.find('a',text="更多产品").get("href")#获取页面文本为"更多产品"的元素的链接
注意当class属性值中间有空格时,这个时候是复合标签,定位复合class最好使用字典。
from selenium.webdriver import Chrome
from bs4 import BeautifulSoup
driver = Chrome(r"C:\\Users\\A\\Downloads\\chromedriver_win32_1\\chromedriver.exe")
driver.get("https://www.baidu.com/")
b = BeautifulSoup(driver.page_source,"html.parser")
b.find('span',{'class':'bg s_ipt_wr iptfocus quickdelete-wrap'})









 175
175




 到【灌水乐园】发言
到【灌水乐园】发言






